youtube-dl is a very feature packed command line video downloader. Contrary to what the name might make you think, it supports way more sites than YouTube. 240 as of 5700e77.
What makes this possible is the structure of ytdl and its awesome community: all the common stuff (CLI, Downloading, Postprocessing) is in the core, and websites support is added in a plugin fashion (with a lot of helper functions available). So anyone can add support for its favorite video site by using another plugin as a template, with no need to understand the whole codebase. And a lot of people indeed did: we’re nearing 500 Pull Requests!
So, what I’m going to show you today is how to add support to ytdl for a simple site (I picked Vine for the tutorial) and how to contribute to ytdl in general.
How ytdl is organized
The website plugins are called Information Extractors – IE – and their role is clear and simple:
- they describe what URLs they are able to interpret (with a regex)
- they get a input URL, usually interact with the site and return a dictionary of information about the video, including its video file URL and its title (over-simplified)
You can find IEs in youtube_dl/extractor.
The rest of ytdl deals with parsing the input arguments (youtube_dl/__init__.py), downloading the file (youtube_dl.downloader) and post-processing (youtube_dl.postprocessor)
Let’s get started
Of course, if you didn’t already git clone ytdl GitHub repository and make sure it’s up-to-date.
Remove the existing Vine IE if you want to follow along the tutorial step by step
1 2 | |
Anatomy of a IE
We already know that a IE is found in youtube_dl/extractor, but how does it look like?
Each site has its own file, named lowercase_site.py. Inside it, a subclass of youtube_dl.extractor.common.InfoExtractor named CameCaseSiteIE is defined.
That subclass has a property, _VALID_URL, a regex that defines what URLs will be handled by the IE (a re.match is performed) and is usually reused to extract for example the video id.
The only other thing needed is the _real_extract method. It takes a URL as its only argument and return a list of dicts, one for each video (usually just one), with at least the following fields:
id: a short video id, should be unique for the site, usually it is site-internalurl: the URL of the actual downloadable video fileext: the extension of the video filetitle: the human-readable full title of the video, all characters allowed, Unicode possibly
So, this is how our bare VineIE should start looking like:
1 2 3 4 5 6 7 | |
Finally, each IE is imported inside youtube_dl/extractor/__init__.py to be exposed. So, you’ll want to add a line like this to that file (please note that the IEs are alphabetically sorted)
1
| |
Just this line will be enough.
A note about syntax: ytdl is a Python2/3 double codebase – that means, it runs both on Python 2 and Python 3, so be careful to use features and statements that are cross-compatible. You’ll find all the compatibility imports already done for you in youtube_dl.utils.
How to run it
Before digging deeper, let’s see how to test-run our development ytdl.
Since youtube_dl is a executable Python package, you can run it from inside your working directory like this
1
| |
So to run our Vine IE we would use something like
1
| |
That indeed does not generate any output or error, great.
Now let’s look at Vine
The first thing you want to do is get a bunch of different videos from your target site, and try to spot the differences. In particular, start with the URL pattern and test assumptions about what parts of it are required or optional.
Here is a Vine for you: https://vine.co/v/b9KOOWX7HUx
The Vine URL pattern is really simple “https://vine.co/v/VIDEO_ID” so we can rewrite _VALID_URL as:
1
| |
So we can start doing some useful stuff in _real_extract:
1 2 3 4 5 | |
InfoExtractor._download_webpage downloads a webpage logging progress (this is what video_id is used for) and handles errors.
Feel free to add a print webpage at the bottom of the function and run with python -m youtube_dl https://vine.co/v/b9KOOWX7HUx to check that everything is working.
The fun part: reversing
Ok, so we have the page HTML and we know what we want to extract, now let’s dissect the page to get our file out.
For this I usually turn to Chrome and its Developer Tools. The Network tab is invaluable in identifying what your final goal is, and so what you should be looking for.
However Vine is really friendly, and a simple right-click > Inspect Element on the playing video will be enough
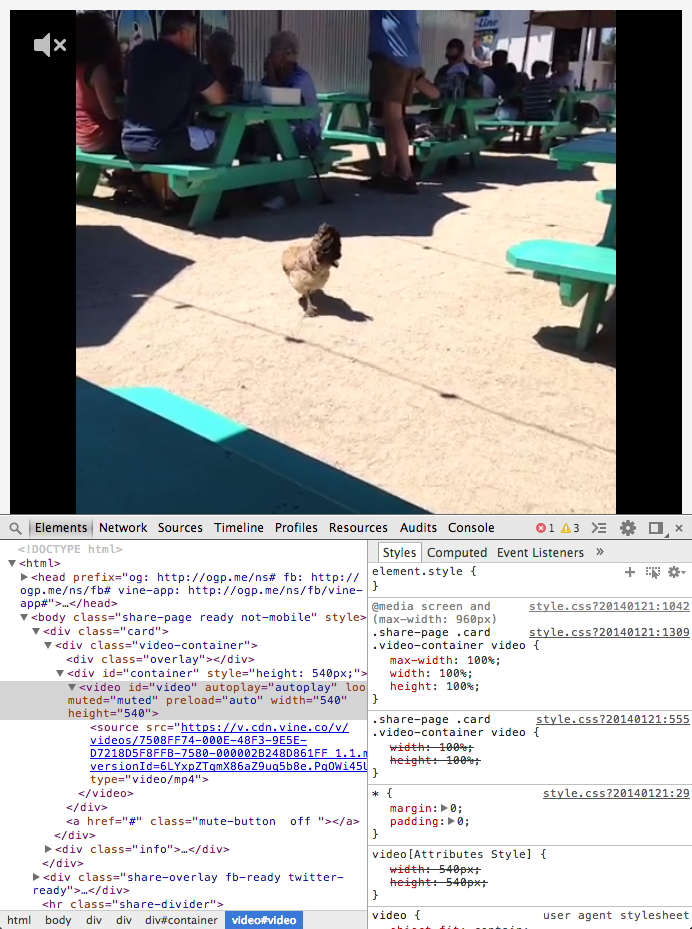
So, we just have to get the mp4 URL out of the source tag. Tip: use the Developer Tools to spot what you’re looking for, but then build your regex based on the actual page source, as pretty printing WILL get in your way and the live DOM might be substantially different from the source.
A regex like this should fit: <source src="([^"]+)" type="video/mp4">
Here comes the next step in our IE:
1 2 3 4 | |
InfoExtractor._html_search_regex, as above, is a helper function that does the boilerplate searching, logging and error handling for you.
Only the title to go. Again, modern pages help: we can piggyback on Facebook-targeted OpenGraph metadata to reliably extract the title

Aaaand, there’s a helper for that! The whole InfoExtractor._og_search_* suite.
Let’s put this last piece in place and return our data
1 2 3 4 5 6 | |
Note: there are better ways to parse HTML than regexes, but ytdl is Public Domain and self-contained, so using external libraries is not an option.
Finish
Putting it all together, this should be more or less your final result
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | |
With this few lines of code, you get all the power and the features of ytdl, for a new site!
Now just run it, sit back and enjoy (and test a bunch of videos to be sure!)
1 2 3 4 5 | |
Finally, please submit a PR to get your IE included in ytdl. Don’t worry, if it downloads, we will be happy to merge it, and if it doesn’t, we will be happy to help!
Ah, add a test
Forgot to mention, ytdl has a complete testing system built in. It is really important that you add a test to your IE before submitting it, as otherwise it would not be possible to do maintenance of so many IEs that break all the time when sites change layout.
Try to write one for each video or URL type.
You just need to add a _TEST dict property (or a _TESTS list of dicts) looking like this:
1 2 3 4 5 6 7 8 9 10 | |
The properties are as follows:
urlis the input URLmd5is the md5 hash of the first 10KB of the file, to get it download the video with the--testflag and runmd5sumon itinfo_dictis just a dict of fields that will be checked against the_real_extractreturn value (missing fields will be ignored)-
`file` is the filename of the resulting video, with this format “`{id}.{ext}`”fileis deprecated, simply addinfo_dict.idandinfo_dict.ext
You can run a single IE test on all the supported Python environments using tox
1 2 3 4 5 6 7 | |
In the next article we will have a look at how to write a IE for a more picky/obfuscated video site.