This is the second post speaking about writing youtube-dl IEs, all the basics are here.
So as promised let’s have a look at something a bit more uncooperative: TopVideo.cc.
This is a kind of more shady site: it has changed gTLD at least once, it’s full of ads and fishy stuff and for our amazement, does not really like the idea of being scraped.
First of all: familiarize with the watch flow. I downloaded a CC-BY-SA video from YouTube (turns out you can filter for them!) and uploaded it to TopVideo. Here is it: http://www.topvideo.cc/4w1c85nzsbj0.
Tip: try first with an ad blocker, it will make everything (interacting with the site, inspecting requests…) far more pleasant, easy and secure. If it does not break your browser playback, it won’t break your reverse engineering.
Note: this time writing the _VALID_URL regex and the like is left to the reader. Just consider that the filename or other stuff might be added to the URL and that they were topvideo.tv before. If this confuses you, check my previous post.
Visiting the main link brings us to a page with no content except some scams and a “Proceed to video!” button.
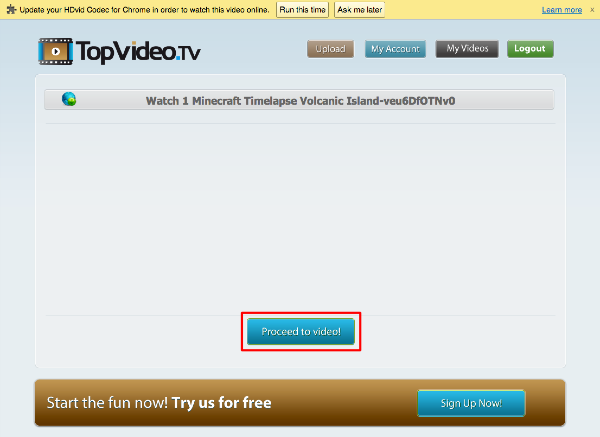
So what is probably happening here is that they are having us acquire some sort of session ticket to see the video, or basically making us go through one more hop of ads/scraping deterrent.
Clicking on the button leads us to the real video page.
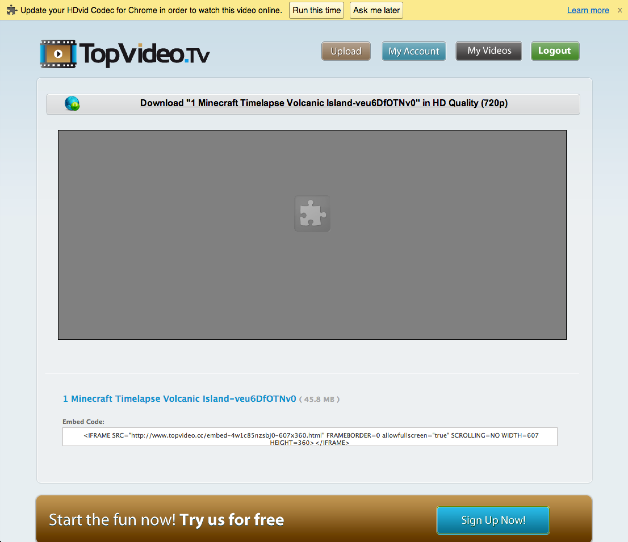
(Let’s take a note of that embed stuff below, if reversing this page turns out to be crazy difficult the embed html might be a softer target.)
So, a Flash player. If we are lucky (the norm) the video URL will be around in the source, in some <script> tag, under names like player options. (If we are not some logic will be embedded in the Flash swf and we will have to emulate that.)
To figure out what we should be looking for we kick open the Network tab of the Developer Tools, start the video, and watch what happens.

No intermediate requests seem to be spawned, and this mp4 starts downloading. Nice. Now, where did it get the url from?
Let’s start grabbing pieces of that url and scouring the page source for them. The long alphanumeric string doesn’t disappoint us, and turns out an exact match. Got you!
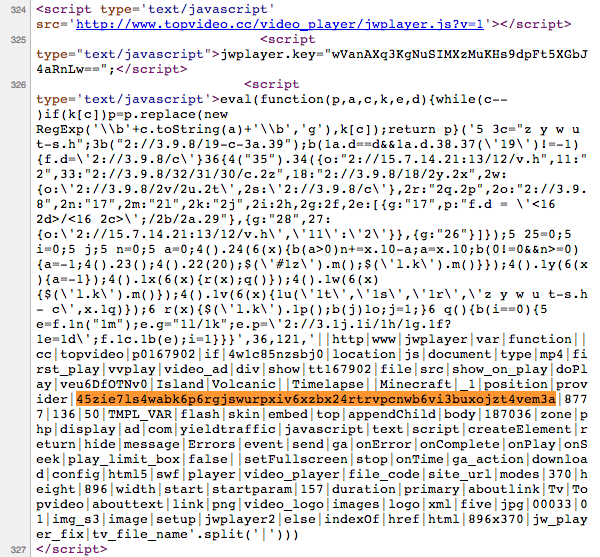
Tip: jwplayer is a good ⌘F target for a lot of sites.
But… Hm. It’s not nice you know? At this point you can either spot that eval at the beginning, turn it to a console.log and have the code deobfuscate for you or be sleep-deprivated as I was at the time and start reversing the thing. (I stopped when jsbeautifier.org kindly deobfuscated it for me.)
Aaaaaand, there it is!

Some Googling will reveal the obfuscator as an old version (?) of dean.edwards.name/packer/ with “Base62 encode” turned on.